Accuracy: de la classification supervisée à non supervisée (clustering)
Posté le Tue 04 June 2019 dans machine learning • Taggé avec evaluation measure, clustering, Python • 4 min read

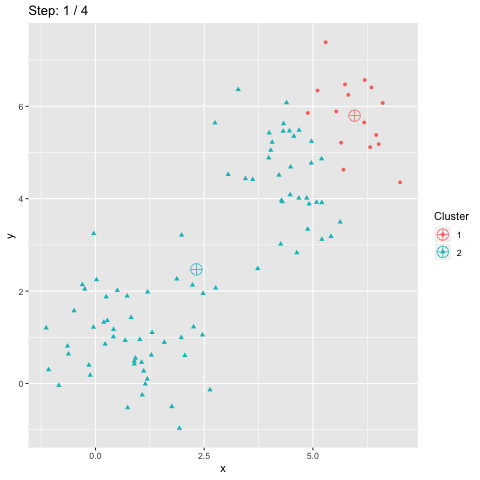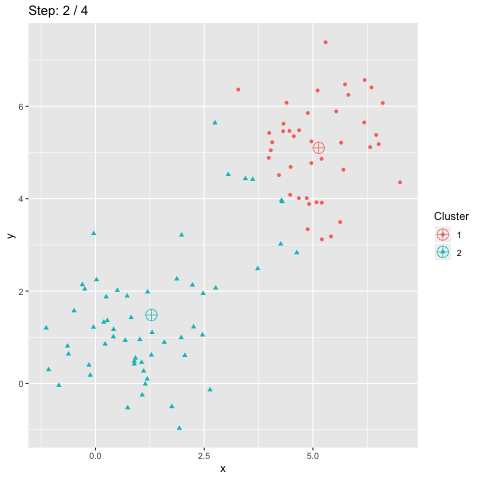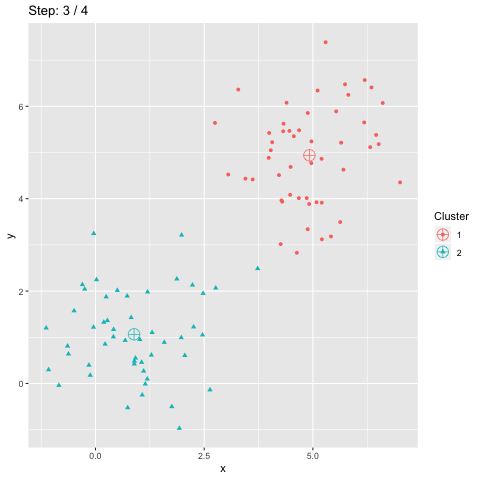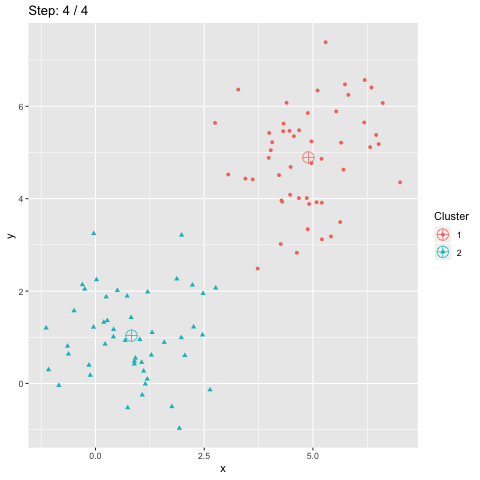
L'accuracy est souvent utilisée comme mesure de qualité pour la classification supervisée. Elle est aussi utilisée pour la classification non supervisée. Cependant, la fonction accuracy_score de scikit-learn ne fournit qu'une borne inférieure de l'accuracy pour le clustering. Cet article explique comment cette mesure peut être calculée pour la classification non supervisée.
Continuer à lire