Accuracy: from classification to clustering evaluation
Posted on Tue 04 June 2019 in machine learning • Tagged with evaluation measure, clustering, Python • 4 min read

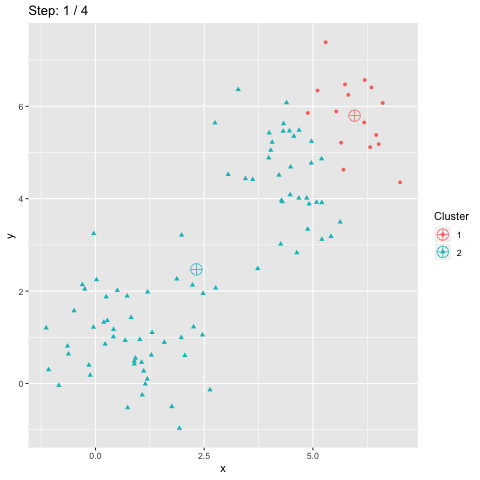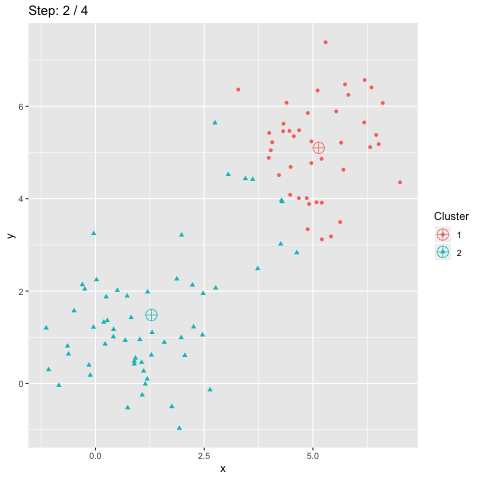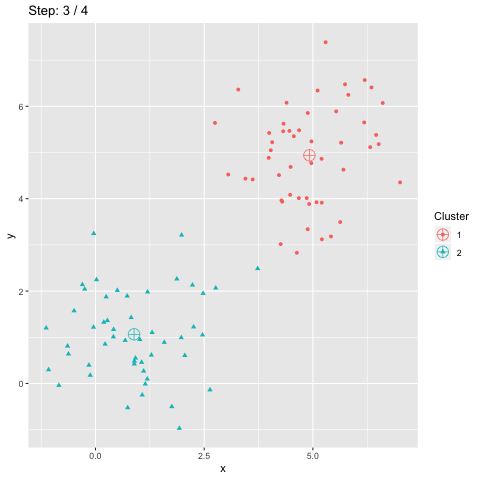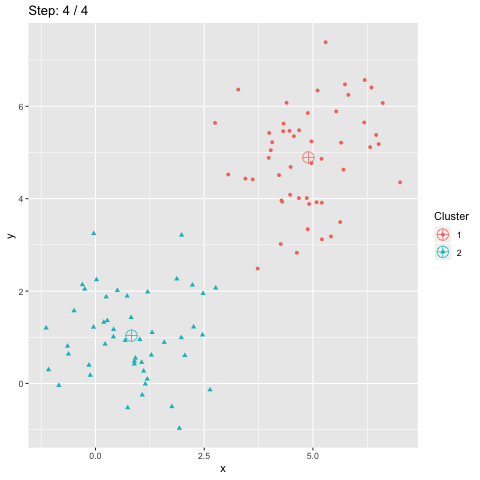
Accuracy is often used to measure the quality of a classification. It is also used for clustering. However, the scikit-learn accuracy_score function only provides a lower bound of accuracy for clustering. This blog post explains how accuracy should be computed for clustering.
Continue reading