Trends in classification and clustering research fields
Posted on Sat 05 October 2019 in Meeting • Tagged with Clustering • 6 min read

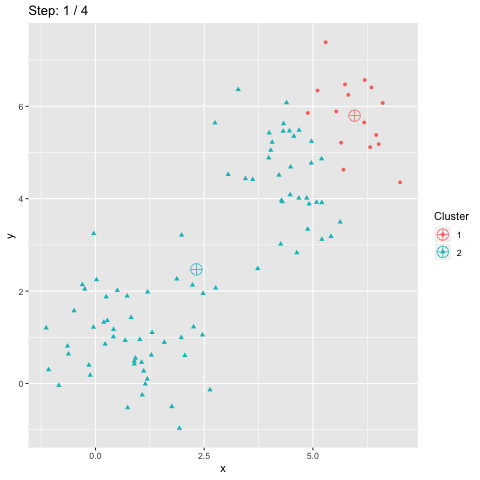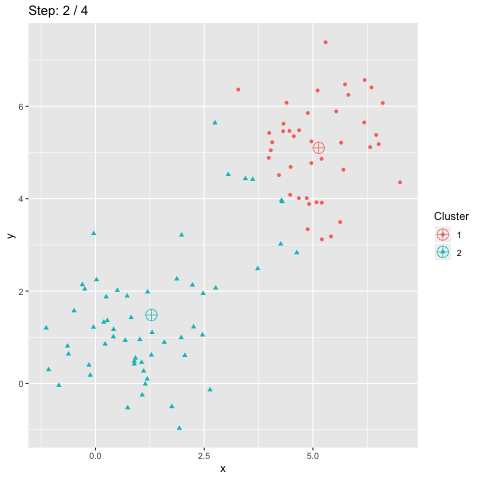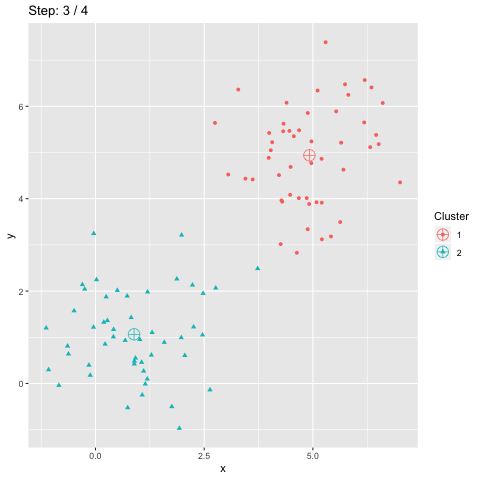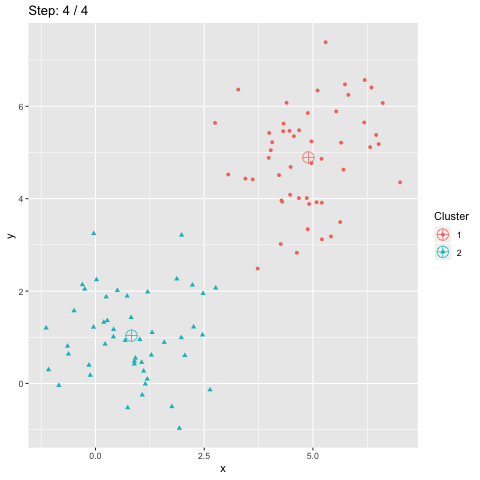
Clustering and classification are ground tasks in machine learning, but still not yet fully solved: Various issues are encountered in data projets to cluster users, images, articles, products, time series data, etc. Here is a brief overview of the works (including mine) presented at the annual french-speaking meeting on this field.
Continue reading